ProblemThe physical–digital traceability gap
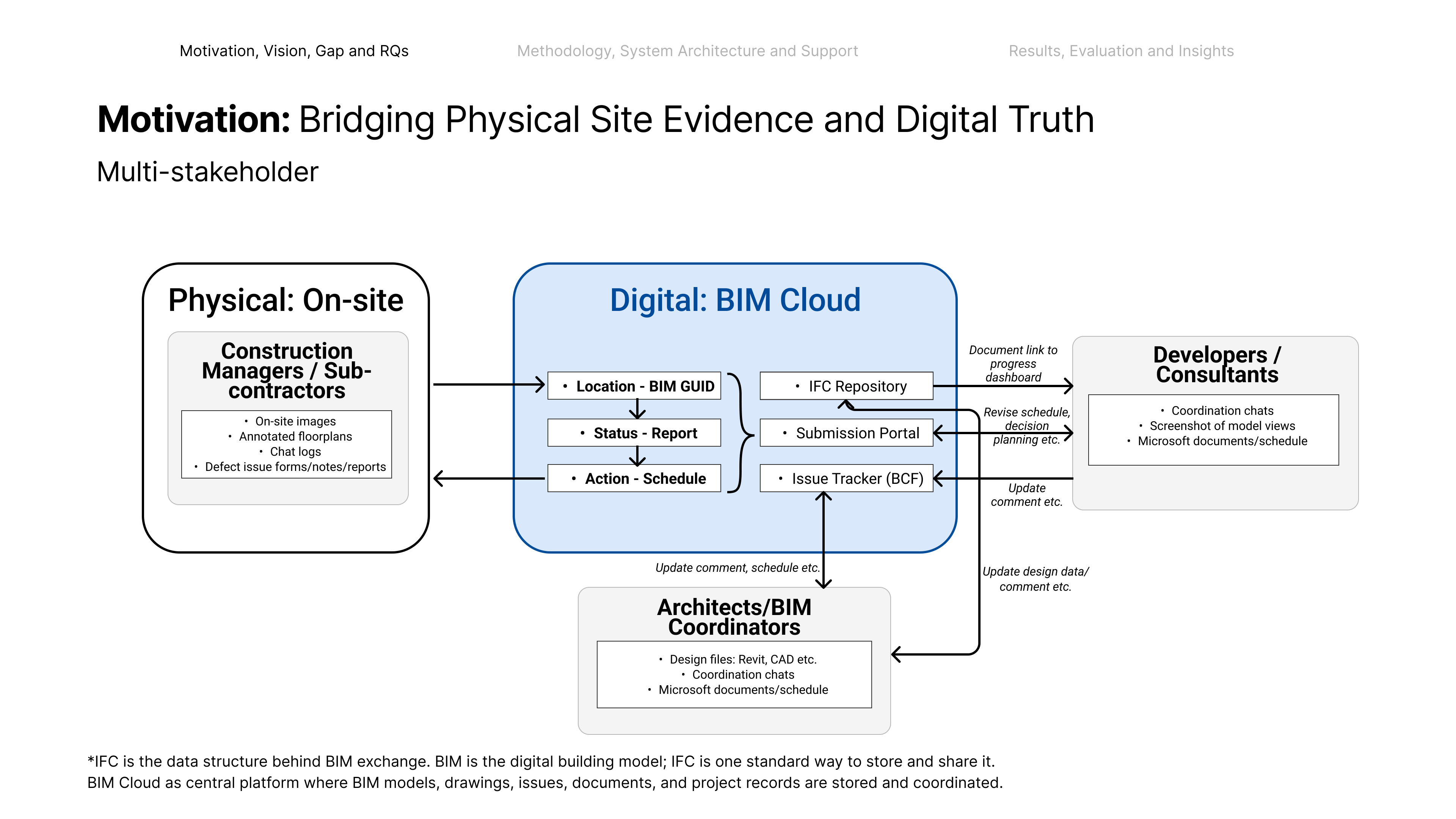
AEC projects standardise on OpenBIM/IFC, yet day-to-day site coordination still runs on manual interpretive labour. Subcontractors log unstructured on-site evidence — photos, chat messages, annotated floorplan patches — into forms; construction managers re-key it into the system. The front-line worker sees a local condition but not the BIM GUID; the coordinator sees the model but not the site context; the developer in the office receives it late and degraded, and plans against it anyway.
Bridging that gap by hand leaks in two ways: semantic drift as detail is re-described and re-typed, and context decay as notes go stale and people roll off the project. It is worst in high-rise work, where dozens of windows and walls are visually identical — a photo of "a window" could be any of them, so even a faithful description never pins down which one.
In a BIM-native workflow every issue should resolve to a GUID linked back to the model, so downstream teams — issue tracking, compliance, planning — inherit it cleanly. Ungrounded records break that chain: not query-able, not traceable, and the decisions built on them arrive late and drift from site reality.
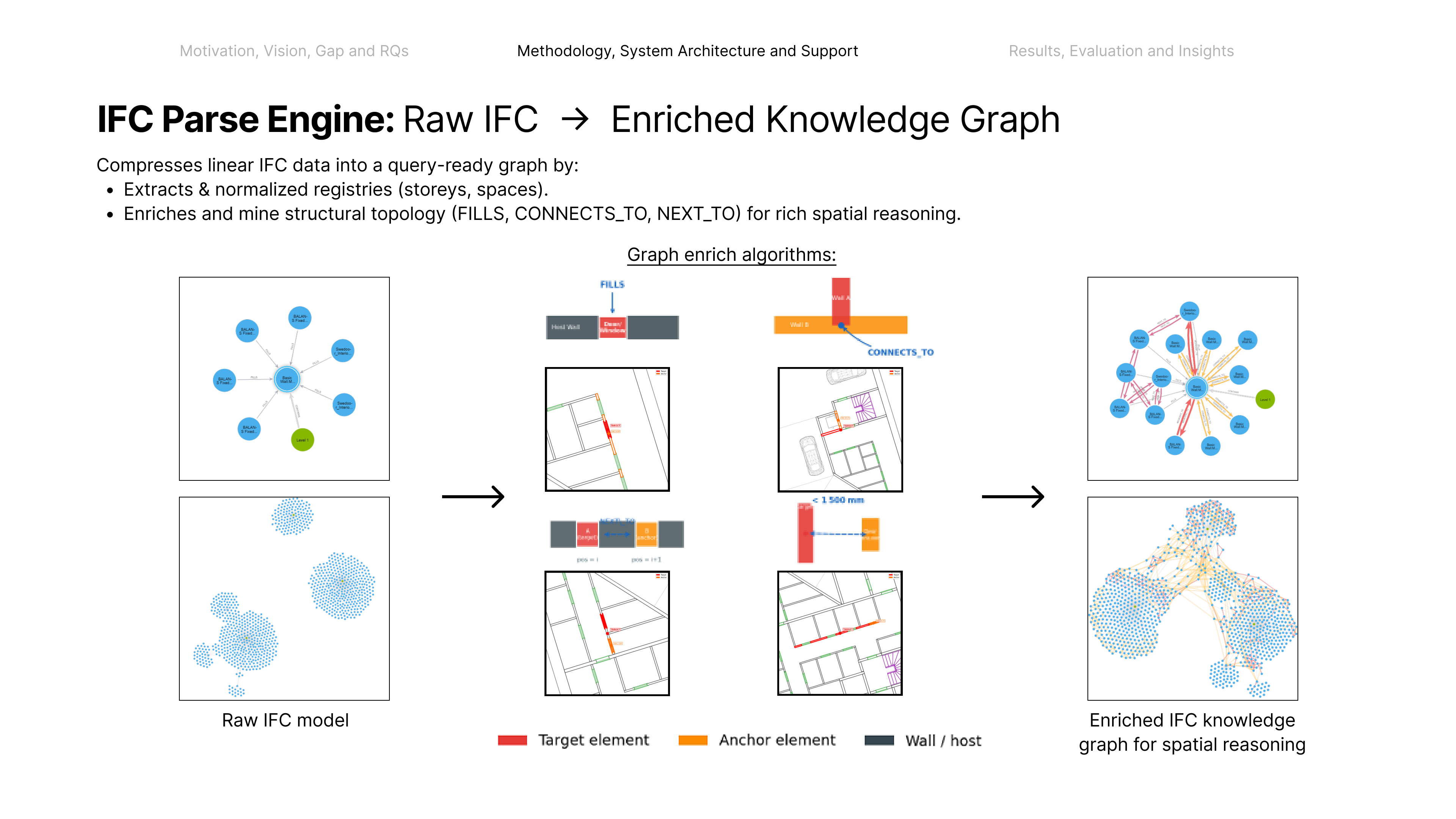
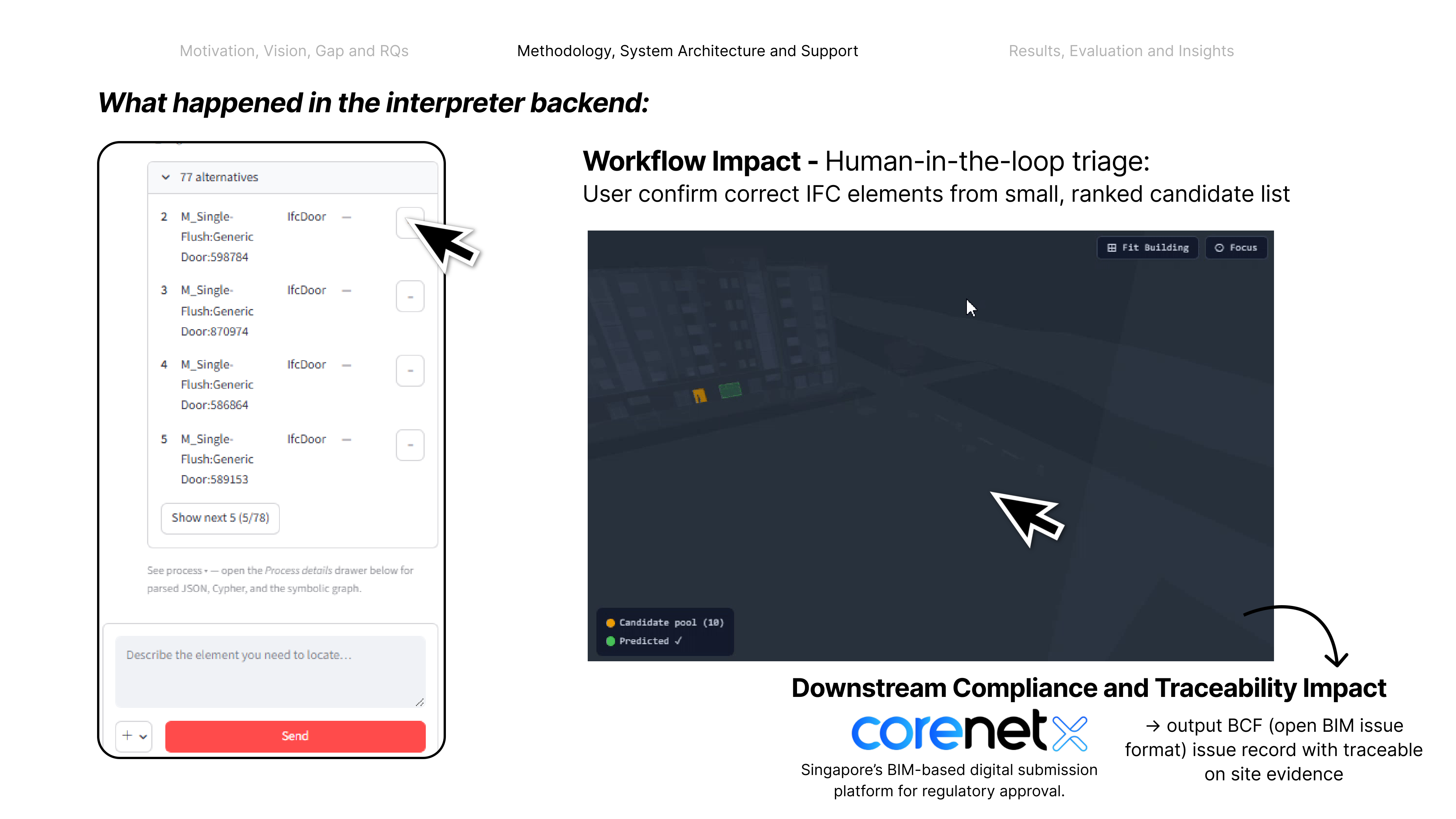
Before any system can reason about what changed or what comes next, it must answer the question that unlocks the rest — where, exactly, is this? That is spatial grounding: a hallucination-resistant link from site evidence to the exact model element. This work introduces an interpreter middleware to close that gap — streamlining data across many stakeholders and formats by making on-site evidence traceable.
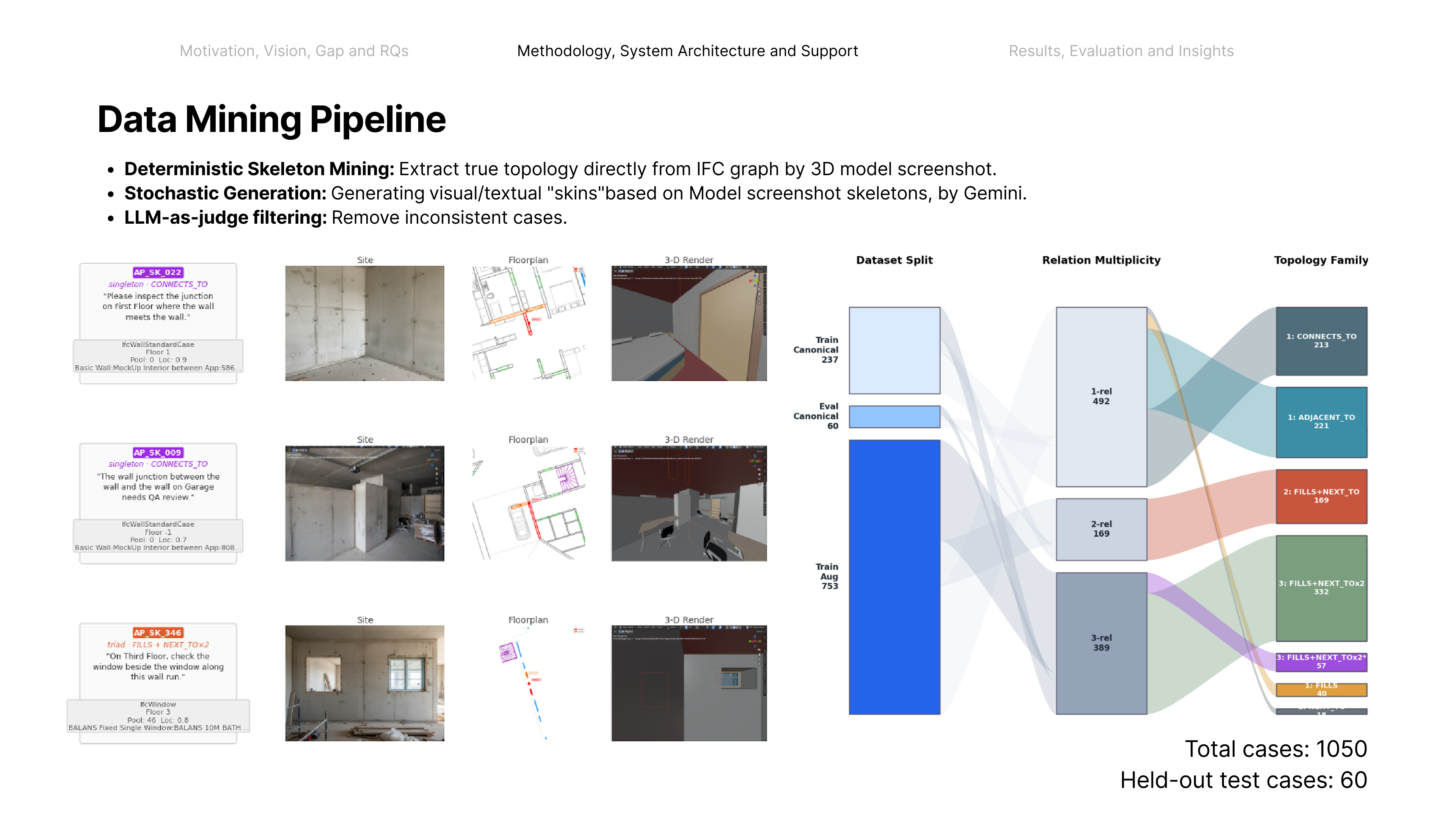
ApproachNeuro-symbolic Architecture Interpreter
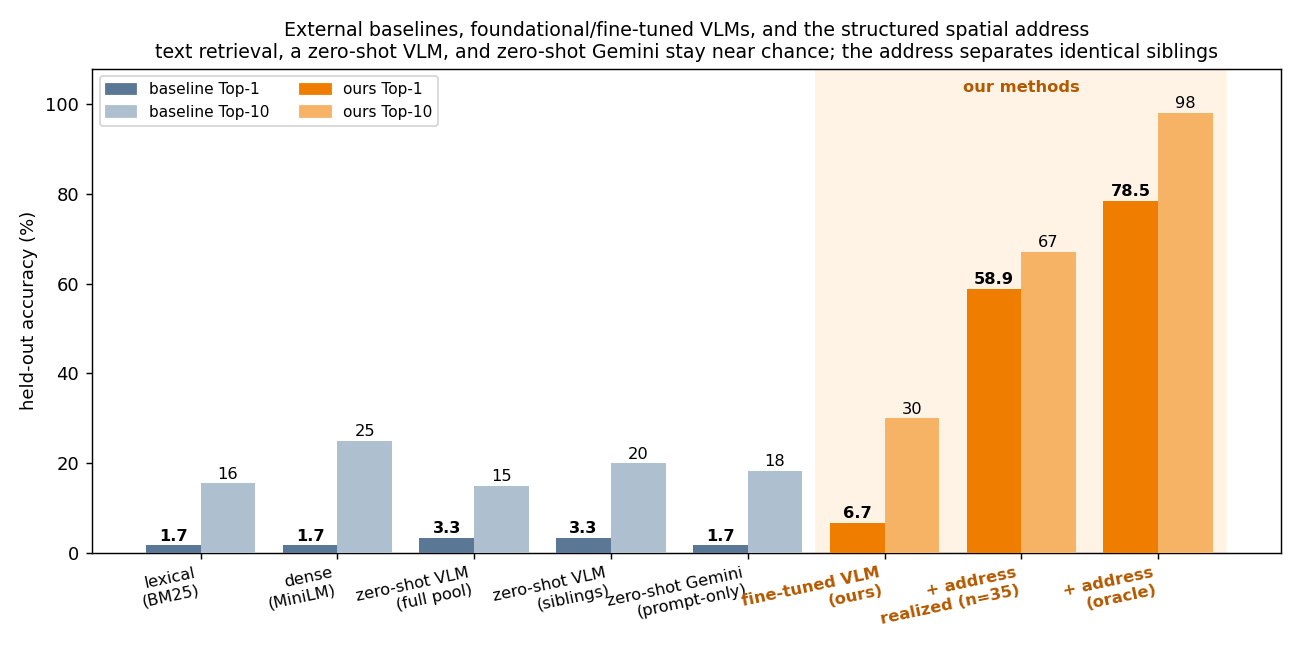
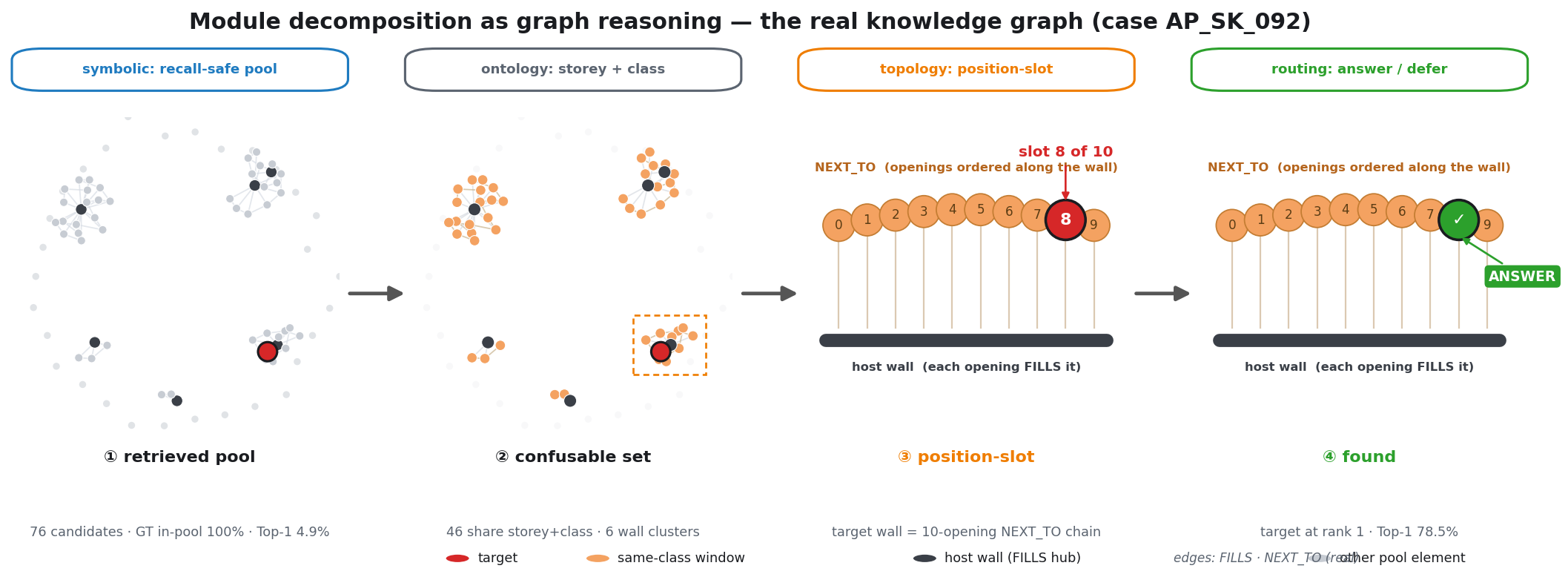
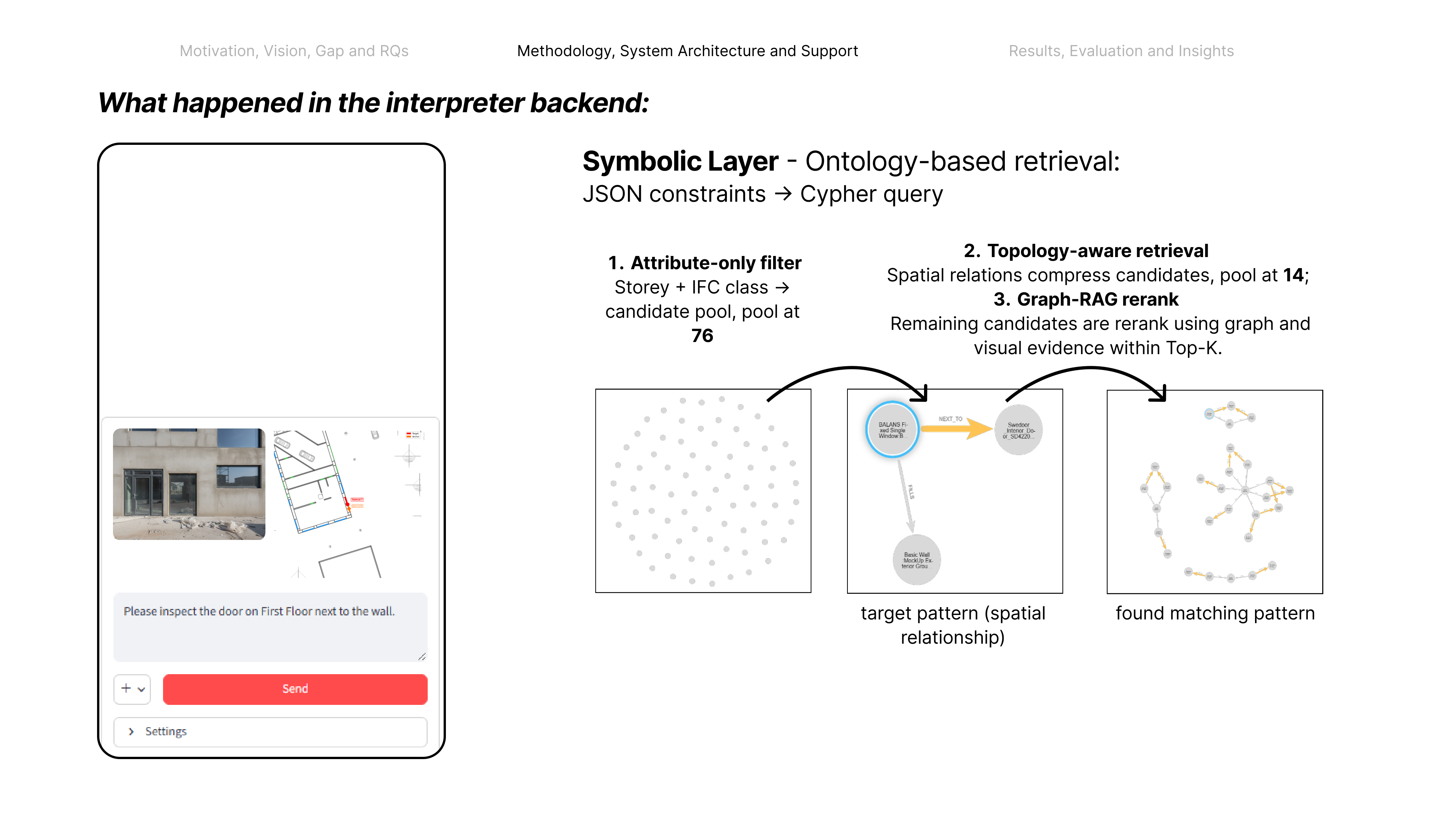
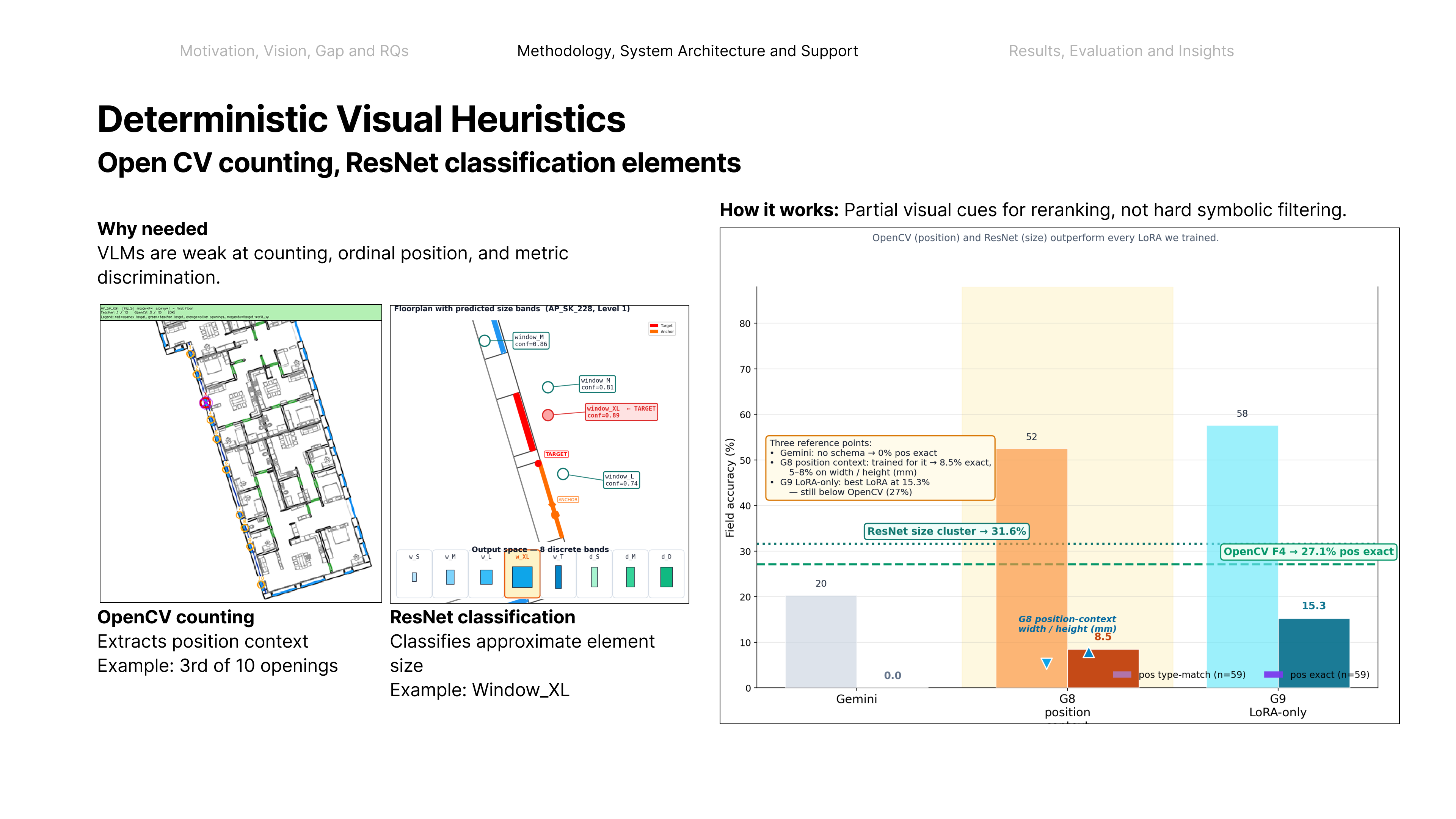
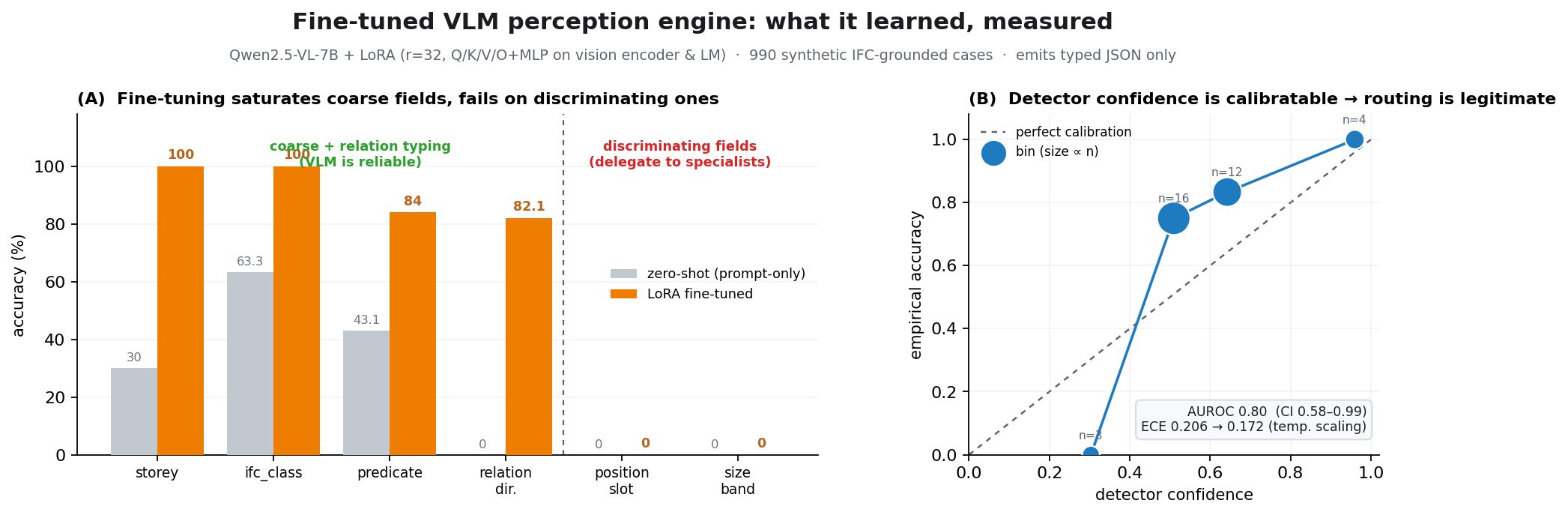
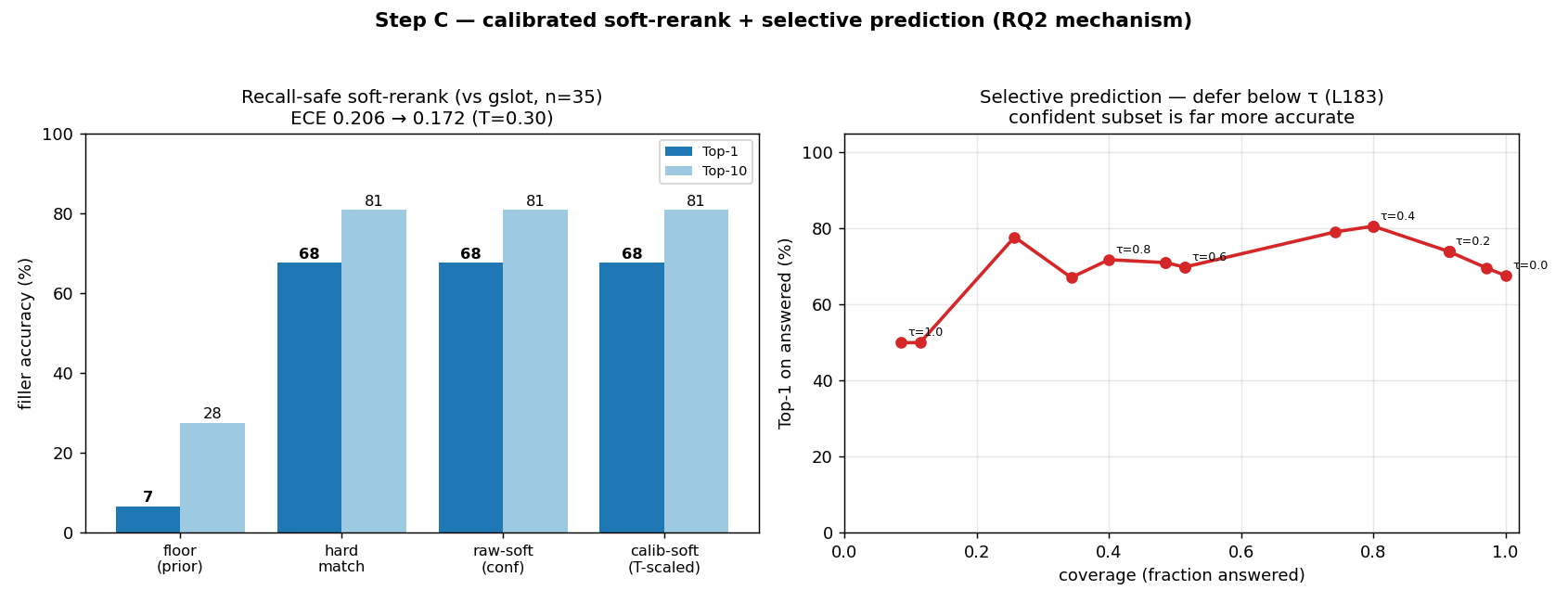
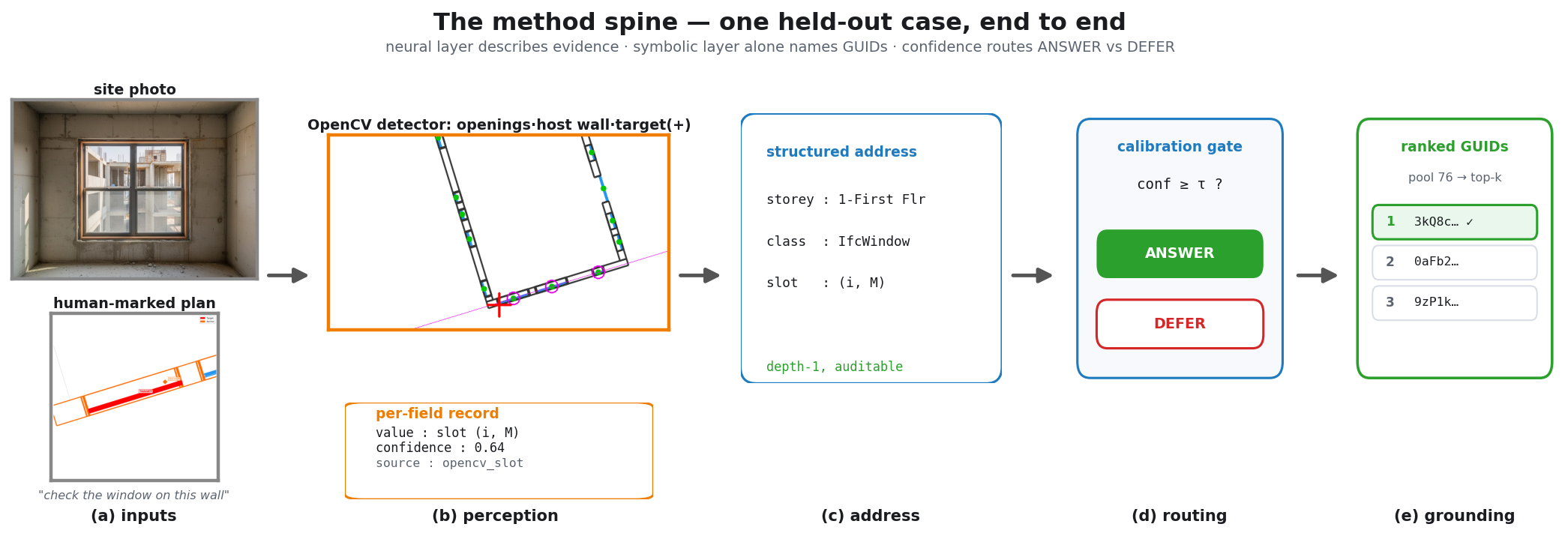
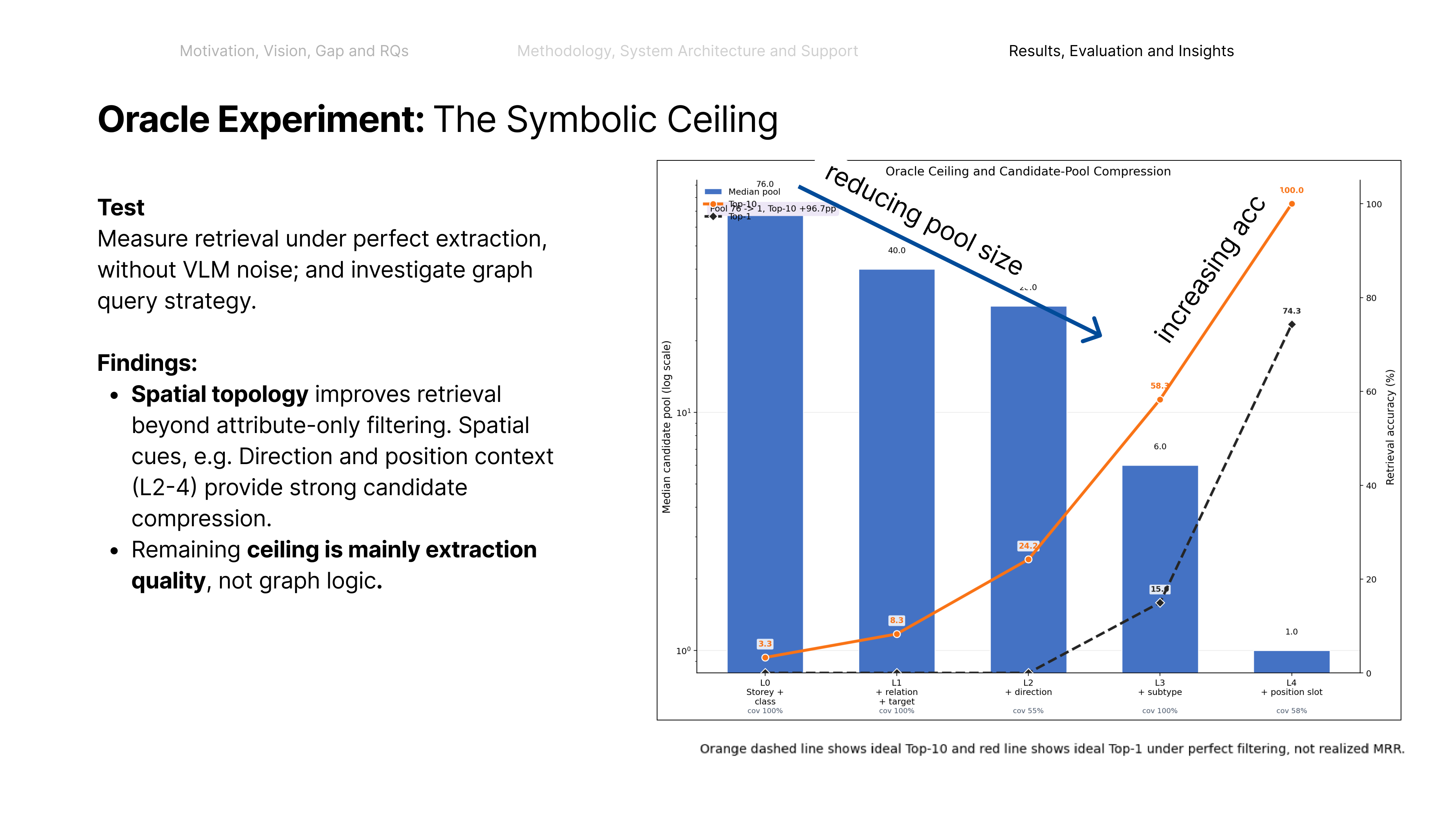
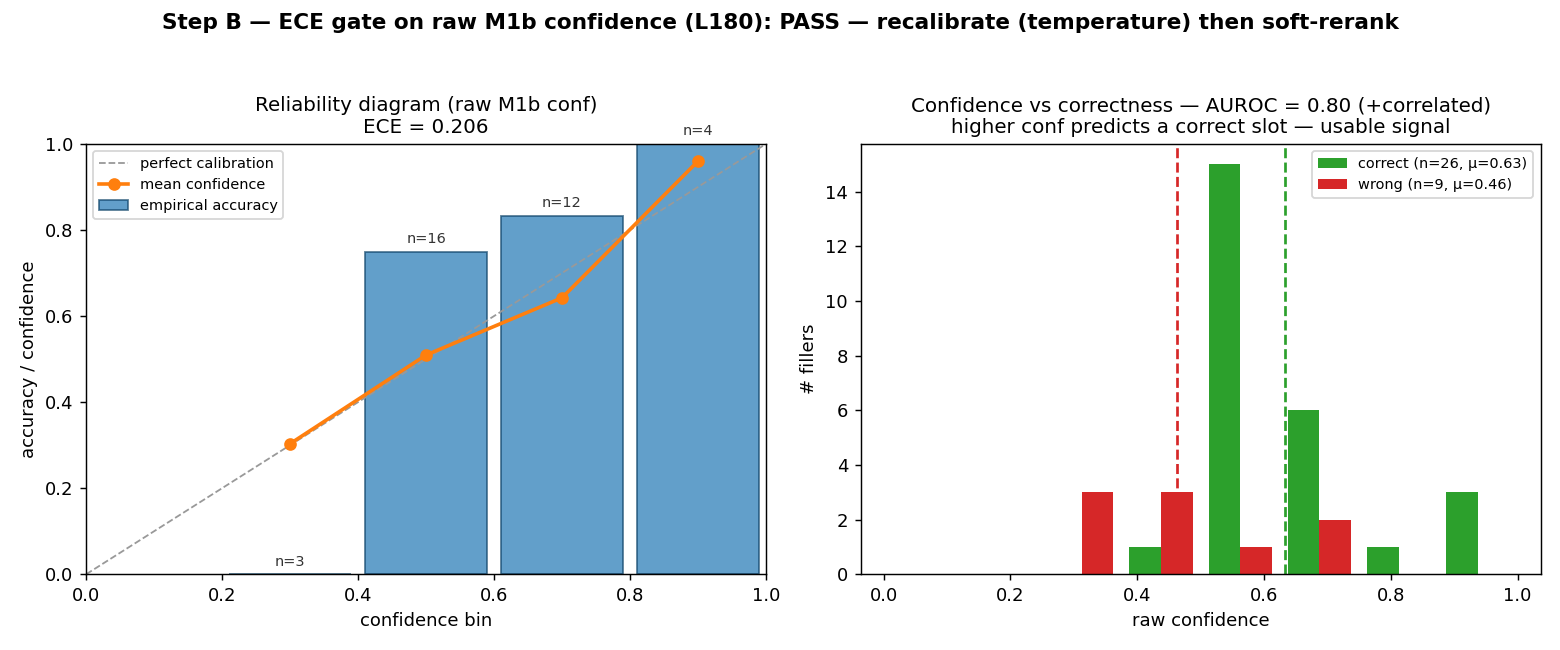
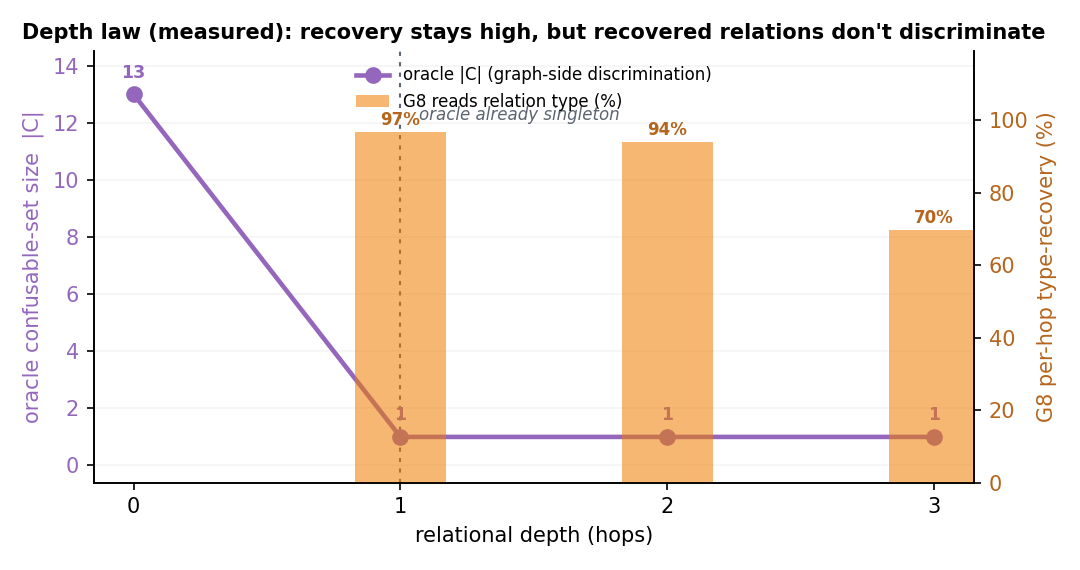
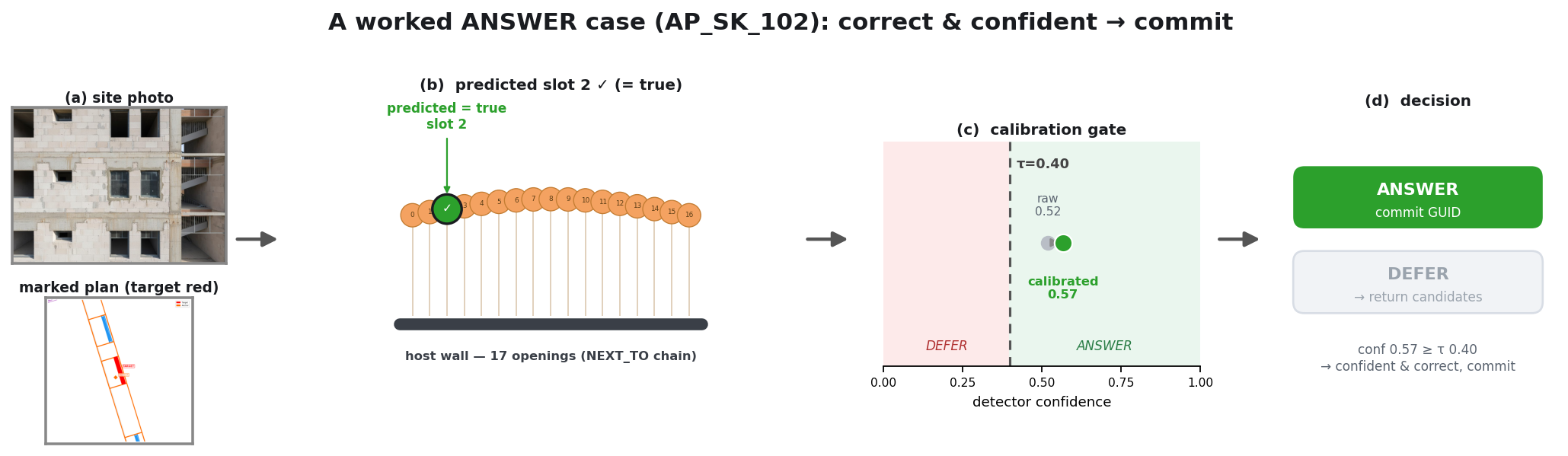
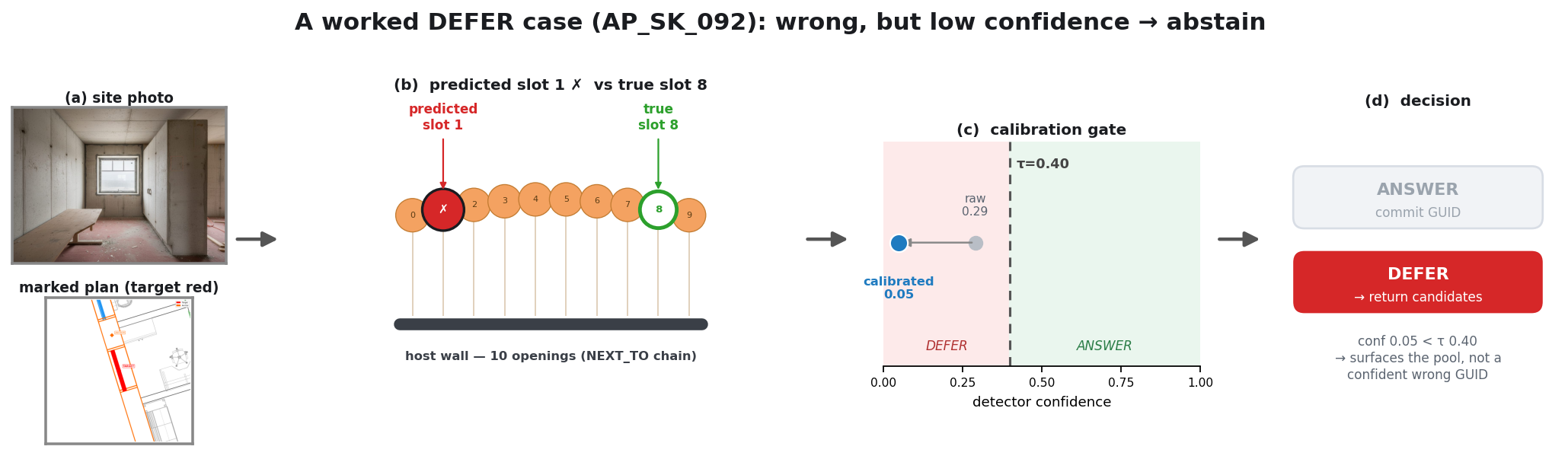
Coordinating AEC projects means constantly translating messy site evidence into the structured BIM record — error-prone, manual work. This paper asks: how can AI act as an interpreter middleware to reliably align unstructured site evidence with digital project data? The answer is a hierarchical neuro-symbolic architecture with two complementary layers. The neural layer is a fine-tuned, domain-specific vision-language model that reads a photo, field note, and plan patch and extracts the typed spatial relationships between elements — the flexible, probabilistic front end. The symbolic layer is a knowledge graph mined from the enriched IFC model: those typed constraints drive a deterministic, priority-ordered traversal that can only return GUIDs that exist in the graph — the hallucination-resistant back end. A deterministic, calibrated soft-rerank produces the final ranked candidates (an optional Graph-RAG/LLM reorder helps only on coarse pools). The load-bearing idea is a type-conditional spatial address — a relational key computable from the BIM model with no labels and recoverable from a flat image. Supplied perfectly it lifts pool right-first from 4.9% to 78.5%; one realized deterministic detector lifts the addressable subset to 58.9% end-to-end, and a calibrated answer/defer gate raises the answered subset to 73.4% — the system knows when to abstain.
Key result: the representation, not a bigger model, separates identical elements